In this blog, we will open SAP HANA Databse in SAP HANA Database Explorer. We will create schema, table and insert data in table. After that we will use Python module to connect SAP HANA and fetch data from SAP HANA Cloud Database.
In first part, we have created SAP BTP Cockpit trial account. If you don't have an account in sap.com, you can follow below like:
How to Setup SAP BTP Trial Account and Create SAP HANA Cloud Database
After login to sap.com. Go to this url: https://cockpit.hanatrial.ondemand.com/trial/#/home/trial. Then click "Go To Your Trial Account".
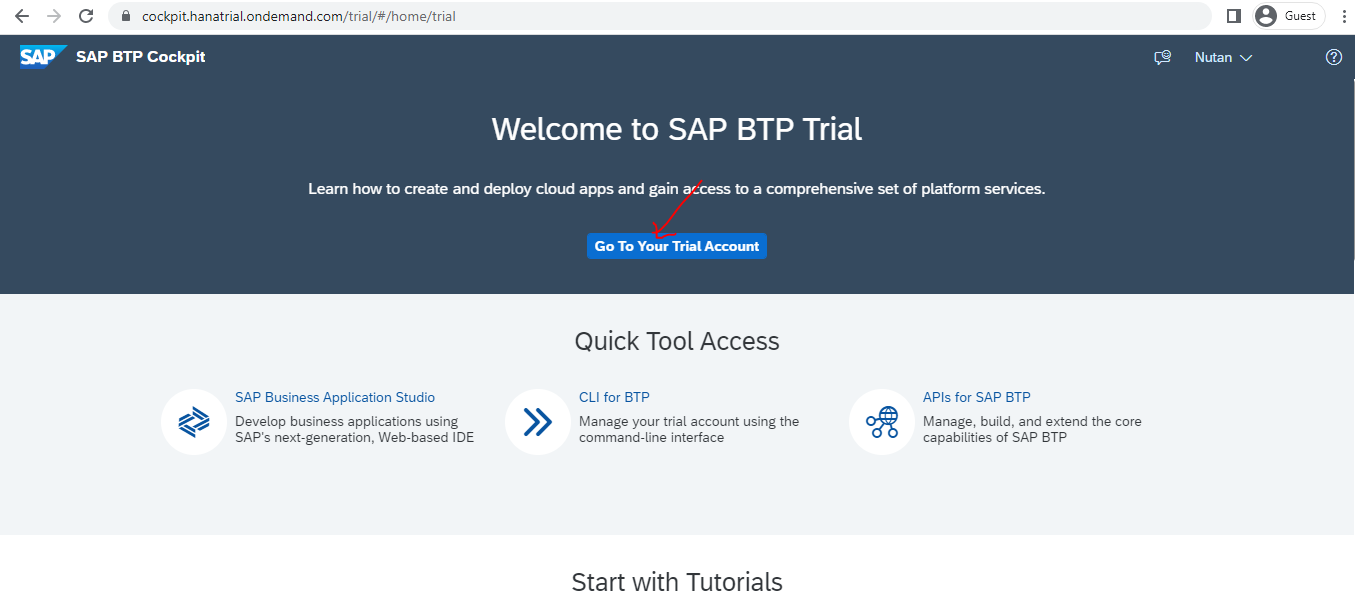
Next screen will show like below. Then click on "trial".
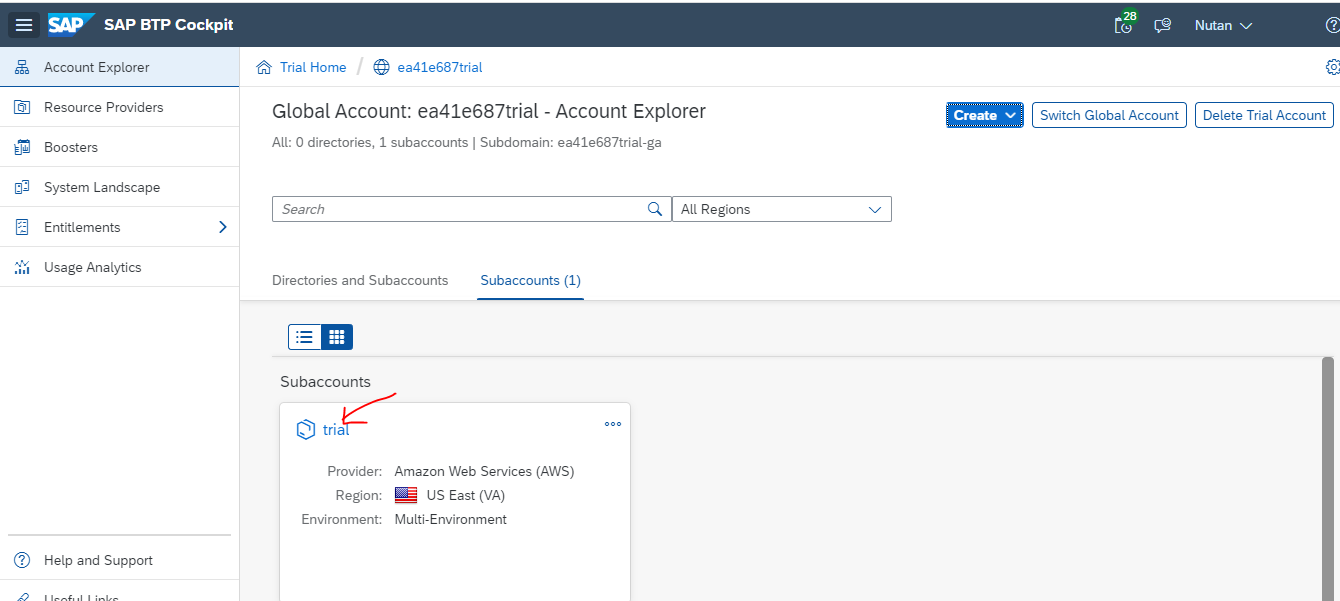
After clicking on "trial", next screen will show like below. We need to click on "dev".

In next screen, we need to click on "SAP HANA Cloud".
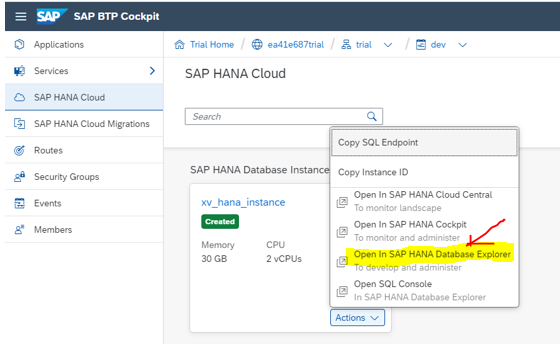
In next screen -> Click on "Actions" -> "Open in SAP HANA Database Explorer".
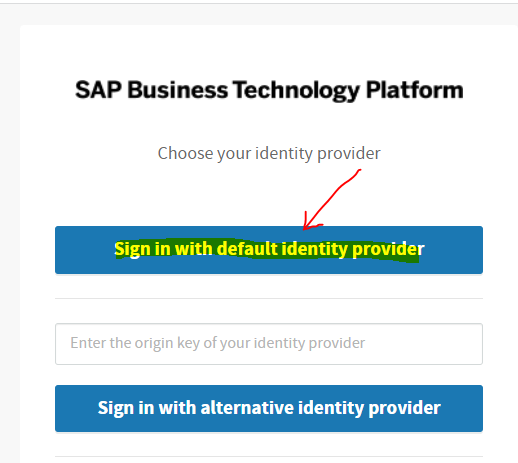
It will ask the "Choose your identity provider", click on "Sign in with default identity provider".
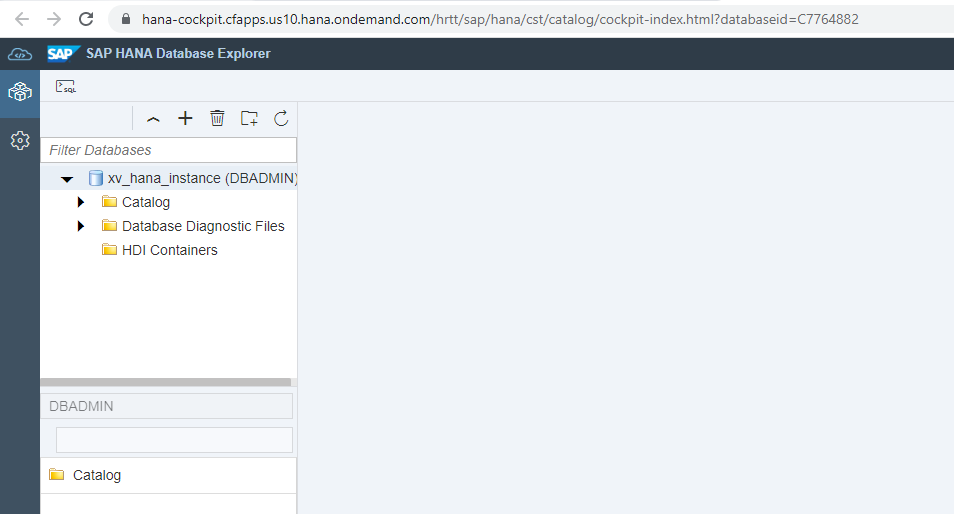
Next screen will show like below. Now SAP HANA Database instance opened in SAP HANA Database Explorer.
Right click on "Schemas" -> "Open SQL Console".

Create schema in SQL Console. In this example, i am creating schema called hotel. Then click on Run.
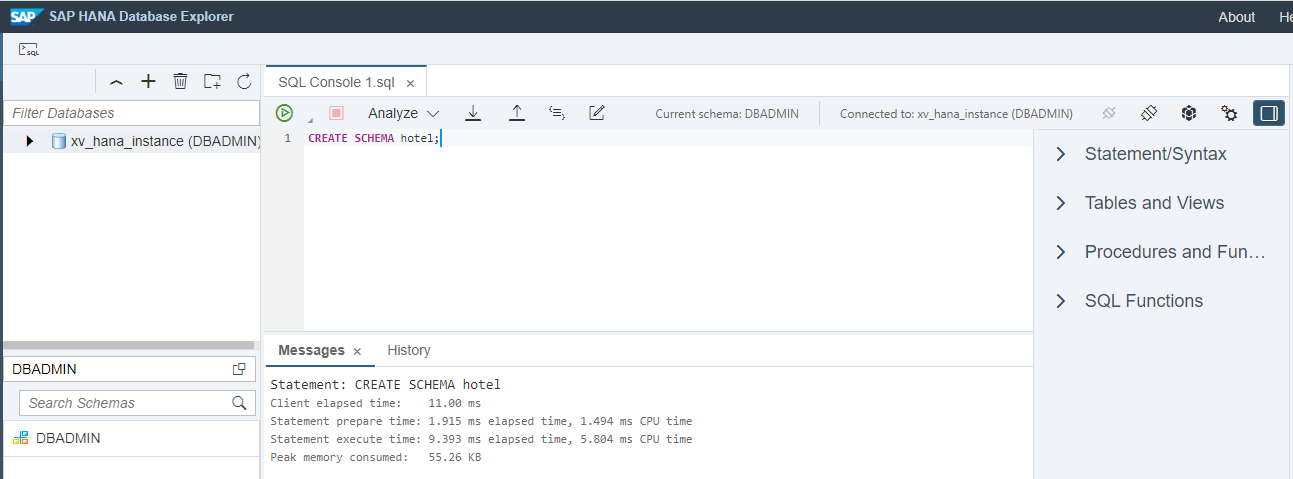
Schema created successfully.
Create table called customer. Then click on Run.
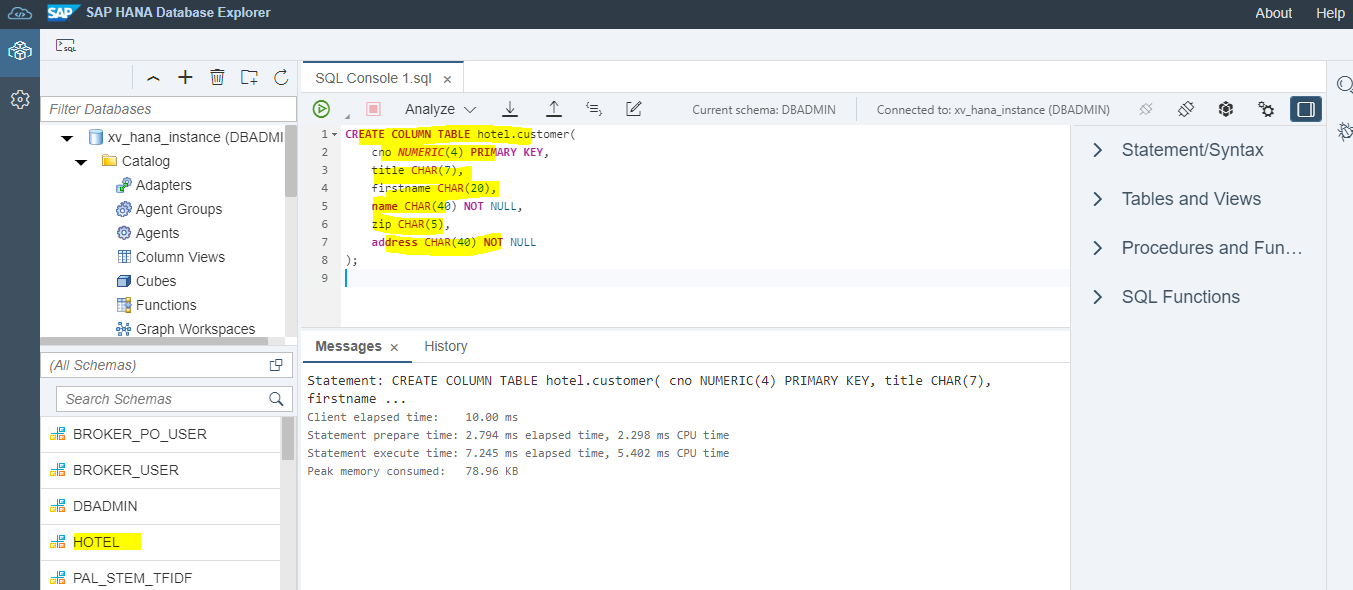
We can see, table customer created successfully.

Record inserted in customer table.
If you want to see table and data, you select "Table", which is showing on the left side -> Then select Table which you want to see. Here i am clicking on Customer -> then click on "Open Data".
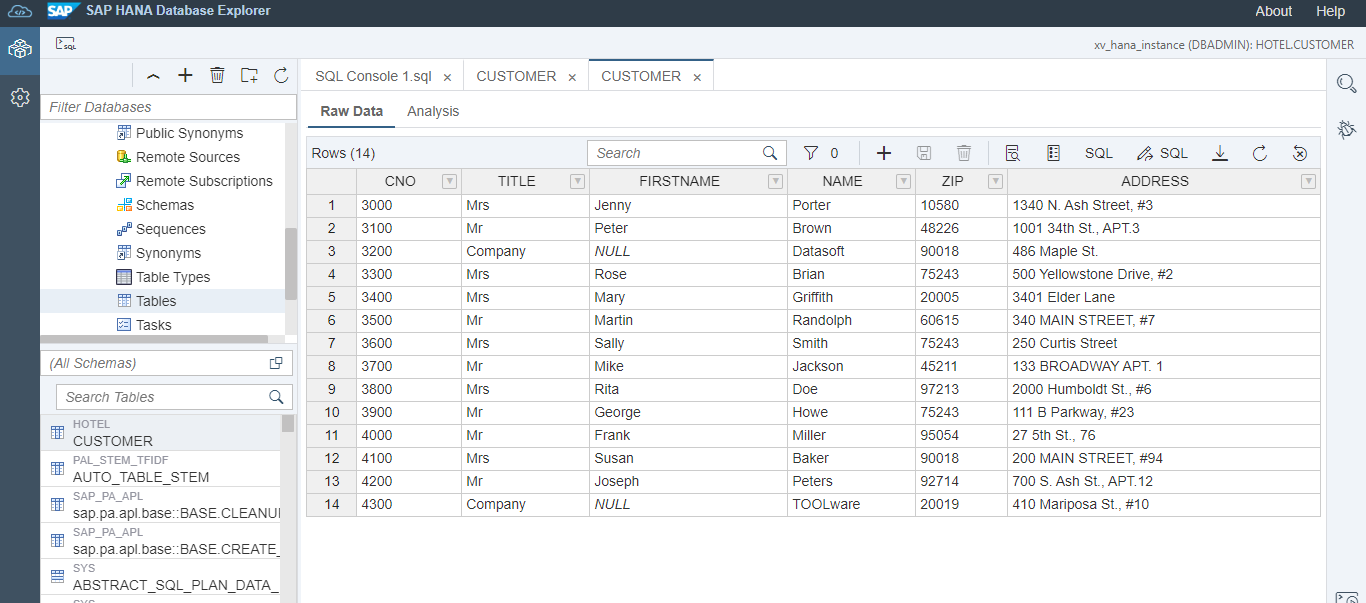
You can see raw data of customer table like below:
Now let us pull this customer data through python. For that we need to install SAP HANA(hana-ml) module.
This package enables Python data scientists to access SAP HANA data and build various machine learning models using the data directly in SAP HANA. This page provides an overview of hana-ml.
hana-ml uses SAP HANA Python driver (hdbcli) to connect to and access SAP HANA.
Python machine learning client for SAP HANA consists of two main parts:
SAP HANA DataFrame, which provides a set of methods for accessing and querying data in SAP HANA without bringing the data to the client.
A set of machine learning APIs for developing machine learning models.Specifically, machine learning APIs are composed of two packages:
PAL package
PAL package consists of a set of Python algorithms and functions which provide access to machine learning capabilities in SAP HANA Predictive Analysis Library(PAL). SAP HANA PAL functions cover a variety of machine learning algorithms for training a model and then the trained model is used for scoring.
APL package
Automated Predictive Library (APL) package exposes the data mining capabilities of the Automated Analytics engine in SAP HANA through a set of functions. These functions develop a predictive modeling process that analysts can use to answer simple questions on their customer datasets stored in SAP HANA.
Create a json file called hana_cloud_config.json in current directory and write database details in that. Then save and close the file.
import json
sap_hana_config_file = "hana_cloud_config.json"
with open(sap_hana_config_file) as f:
sap_hana_config = json.load(f)
db_url = sap_hana_config['url']
db_port = sap_hana_config['port']
db_user = sap_hana_config['user']
db_pwd = sap_hana_config['pwd']
We can print and see the database details.
db_port, db_user, db_url, db_pwd
from hana_ml.dataframe import ConnectionContext
class hana_ml.dataframe.ConnectionContext(address='', port=0, user='', password='', autocommit=True, packetsize=None, userkey=None, **properties)
Bases: object
Represents a connection to an SAP HANA system.
ConnectionContext includes methods for creating DataFrames from data on SAP HANA. DataFrames are tied to a ConnectionContext, and are unusable once their ConnectionContext is closed.cc = ConnectionContext(db_url, db_port, db_user, db_pwd)
cc
If you are not able to connect, you can check your database instance is running or not. If it is stopped, then you can start your database instance.
print(cc.hana_version())
We have to give schema and table name. Here my schema is hotel and table is customer.
hana_ml_df = cc.table('CUSTOMER', schema='HOTEL')
hana_ml_df
SAP HANA DataFrame object is created. We need to transform a SAP HANA DataFrame to a Pandas DataFrame. We can use collect() for that.
df = hana_ml_df.collect()
df.head()
df.info()
df.shape