In this blog, we will convert a word file to pdf and html. Also we will convert pdf to jpg and png file. We will use docx2pdf, mammoth, pdf2image Python modules for conversion.
We have sample.docx file, which we are going to use for this blog. Content in word file:

Convert docx to pdf on Windows or macOS directly using Microsoft Word (must be installed).
pip install docx2pdf
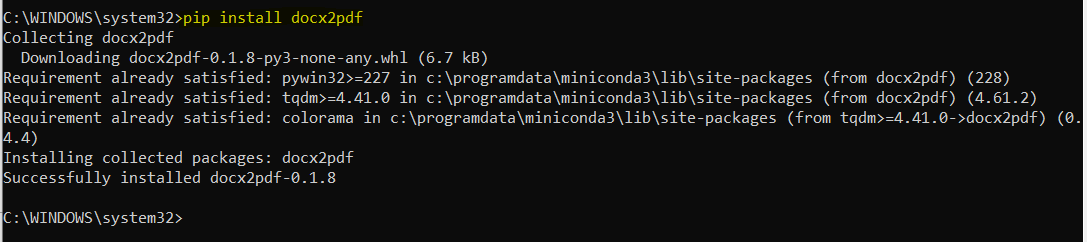
Python module is installed. Open Jupyter notebook and import module.
!dir *.doc *.docx
We have sample.docx file in current directory.
from docx2pdf import convert
folderDir = "E:/jupyter-notebook-workspace/"
inputFile = folderDir + "sample.docx"
outputFile = folderDir + "sample.pdf"
convert(inputFile, outputFile)
!dir *.pdf

Convert Word documents from docx to simple and clean HTML and Markdown.
Mammoth is designed to convert .docx documents, such as those created by Microsoft Word, Google Docs and LibreOffice, and convert them to HTML. Mammoth aims to produce simple and clean HTML by using semantic information in the document, and ignoring other details. For instance, Mammoth converts any paragraph with the style Heading 1 to h1 elements, rather than attempting to exactly copy the styling (font, text size, colour, etc.) of the heading.
pip install mammoth

import mammoth
with open(inputFile, "rb") as docx_file:
result = mammoth.convert_to_html(docx_file)
html = result.value # The generated HTML
messages = result.messages
html
f = open(folderDir + 'sample.html',"w")
f.write(html)
f.close()
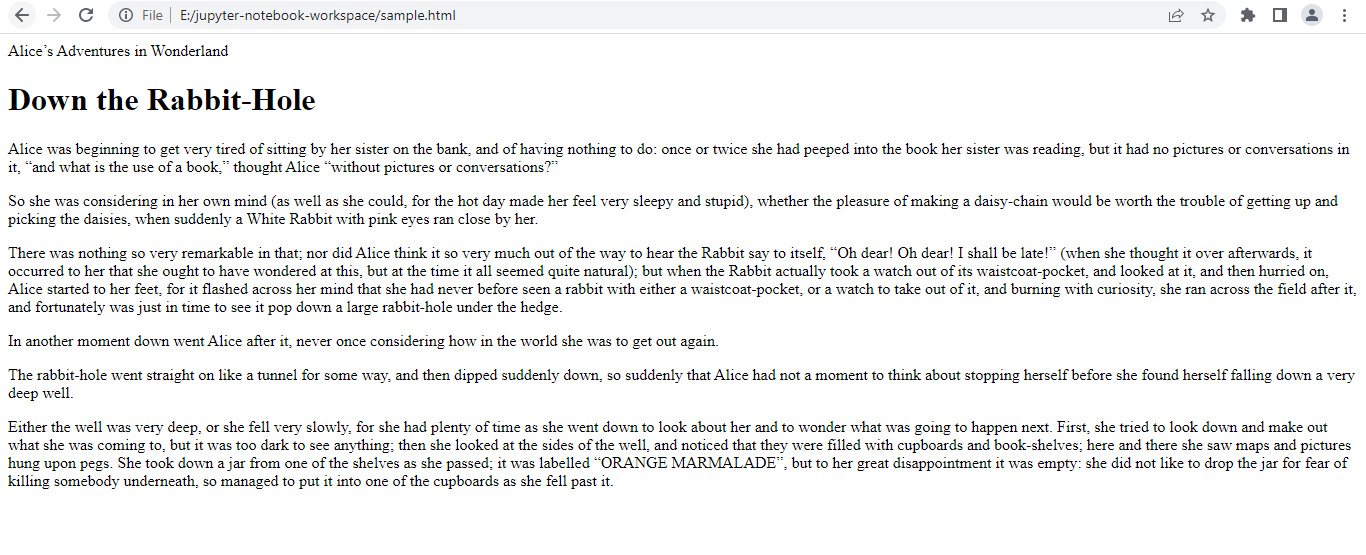
We have saved file in sample.html. Let us view the sample.html.
A wrapper around the pdftoppm and pdftocairo command line tools to convert PDF to a PIL Image list.
Windows users will have to build or download poppler for Windows. I recommend @oschwartz10612 version which is the most up-to-date. You will then have to add the bin/ folder to PATH or use poppler_path = r"C:\path\to\poppler-xx\bin" as an argument in convert_from_path.
Mac
Mac users will have to install poppler for Mac.Linux
Most distros ship with pdftoppm and pdftocairo. If they are not installed, refer to your package manager to install poppler-utils
Platform-independant (Using conda)
Install poppler: conda install -c conda-forge poppler
Install pdf2image: pip install pdf2imagepip install pdf2image

conda install -c conda-forge poppler

from pdf2image import convert_from_path
convert_from_path(pdf_path, dpi=200, output_folder=None, first_page=None, last_page=None, fmt='ppm', jpegopt=None, thread_count=1, userpw=None, use_cropbox=False, strict=False, transparent=False, single_file=False, output_file=<pdf2image.generators.ThreadSafeGenerator object at 0x000002488FC544F0>, poppler_path=None, grayscale=False, size=None, paths_only=False, use_pdftocairo=False, timeout=None, hide_annotations=False)
Description: Convert PDF to Image will throw whenever one of the condition is reached
Parameters:
pdf_path -> Path to the PDF that you want to convert
dpi -> Image quality in DPI (default 200)
output_folder -> Write the resulting images to a folder (instead of directly in memory)
first_page -> First page to process
last_page -> Last page to process before stopping
fmt -> Output image format
jpegopt -> jpeg options `quality`, `progressive`, and `optimize` (only for jpeg format)
thread_count -> How many threads we are allowed to spawn for processing
userpw -> PDF's password
use_cropbox -> Use cropbox instead of mediabox
strict -> When a Syntax Error is thrown, it will be raised as an Exception
transparent -> Output with a transparent background instead of a white one.
single_file -> Uses the -singlefile option from pdftoppm/pdftocairo
output_file -> What is the output filename or generator
poppler_path -> Path to look for poppler binaries
grayscale -> Output grayscale image(s)
size -> Size of the resulting image(s), uses the Pillow (width, height) standard
paths_only -> Don't load image(s), return paths instead (requires output_folder)
use_pdftocairo -> Use pdftocairo instead of pdftoppm, may help performance
timeout -> Raise PDFPopplerTimeoutError after the given timepages = convert_from_path('E:/jupyter-notebook-workspace/sample.pdf')
pages
for page in pages:
page.save('sample.jpg', 'JPEG')
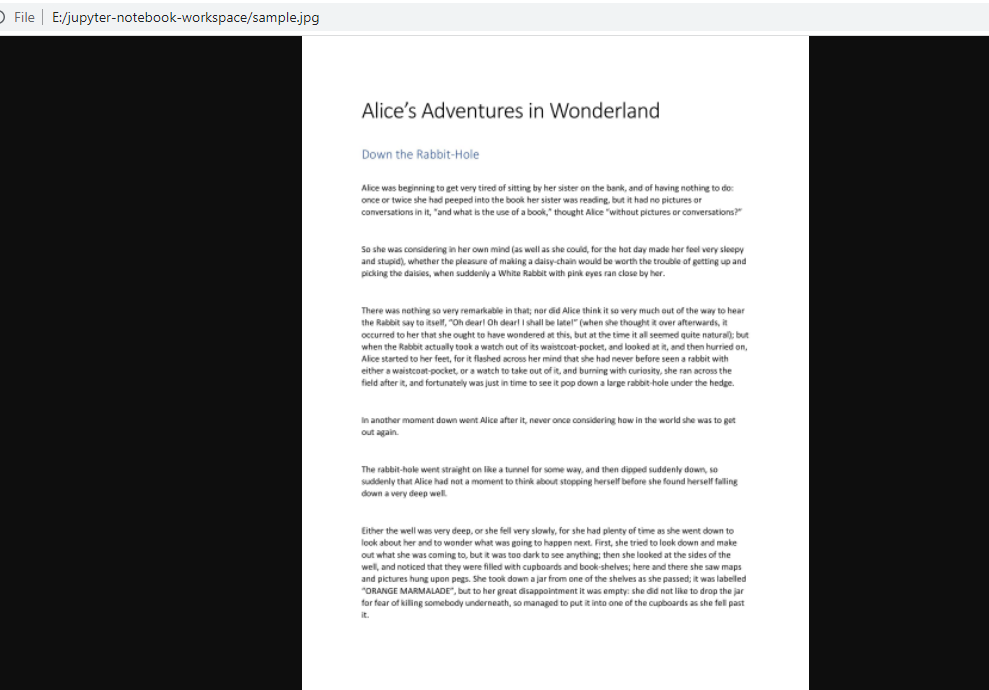
View sample.jpg file.
for page in pages:
page.save('sample.png', 'PNG')
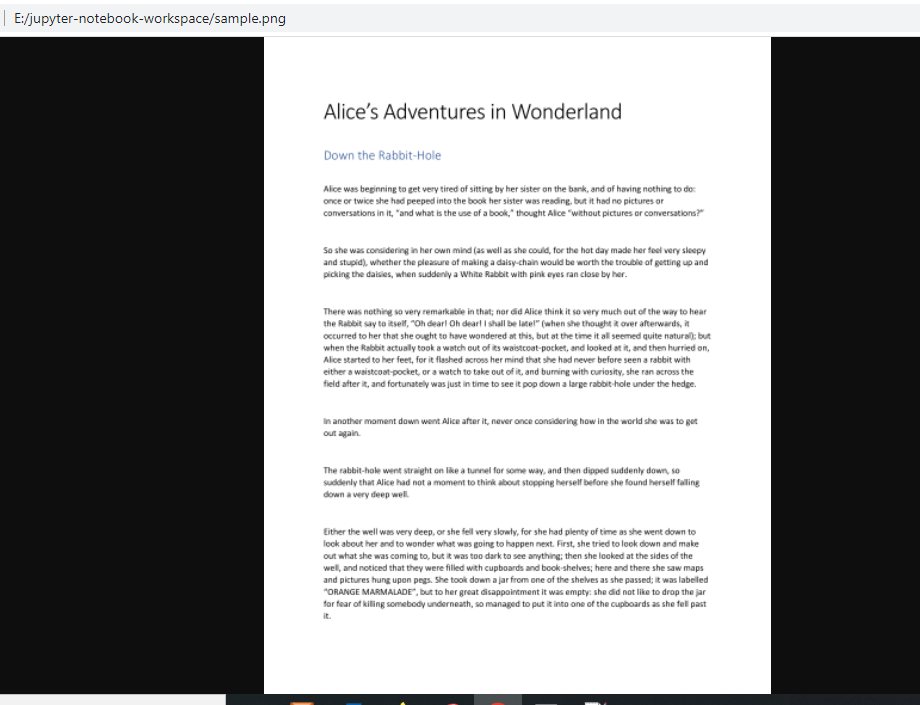
View sample.png file.
Thanks for reading.