
In this blog we will connect to Mysql database, read tables and convert into pandas's dataframe. We will also add some records in mysql table through csv file and pandas dataframe.
SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that gives application developers the full power and flexibility of SQL. SQLAlchemy provides a full suite of well known enterprise-level persistence patterns, designed for efficient and high-performing database access, adapted into a simple and Pythonic domain language.
Python needs a module to interface with MySQL database. For that install MySQL-Python module.
sudo -E pip install sqlalchemy
sudo apt-get install python-mysqldb
sudo -E pip install mysqlclient
import pandas as pd
username = "root"
password = "nutannutan"
port = 3306
database = "test"
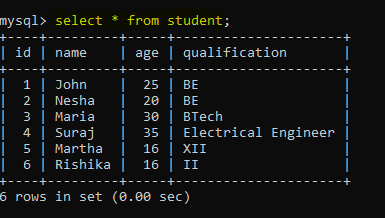
I have several database in my system. I wanted to read one of mysql database called test. You can read database which you have. In my test database i have one table student.

The Engine is the starting point for any SQLAlchemy application. It’s “home base” for the actual database and its DBAPI, delivered to the SQLAlchemy application through a connection pool and a Dialect, which describes how to talk to a specific kind of database/DBAPI combination.
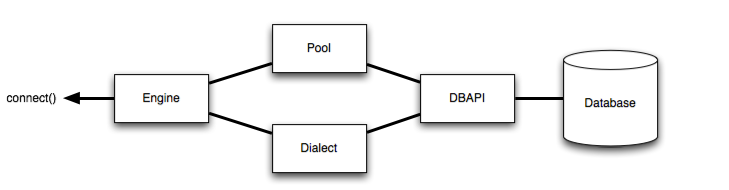
Where above, an Engine references both a Dialect and a Pool, which together interpret the DBAPI’s module functions as well as the behavior of the database.
Creating an engine is just a matter of issuing a single call, create_engine():
#to check mysql url
print('mysql+mysqldb://%s:%s@localhost:%i/%s'
%(username, password, port, database))
engine = create_engine('mysql+mysqldb://%s:%s@localhost:%i/%s'
%(username, password, port, database))
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None): Read SQL query into a DataFrame.
Returns a DataFrame corresponding to the result set of the query string. Optionally provide an index_col parameter to use one of the columns as the index, otherwise default integer index will be used.
Parameters
sql: str
SQL query to be executed.
con: SQLAlchemy connectable, str, or sqlite3 connection
Using SQLAlchemy makes it possible to use any DB supported by that library.
index_col: str or list of str, optional, default: None
Column(s) to set as index(MultiIndex).
coerce_float: bool, default True
Attempts to convert values of non-string, non-numeric objects (like decimal.Decimal) to floating point. Useful for SQL result sets.
params: list, tuple or dict, optional, default: None
List of parameters to pass to execute method. The syntax used to pass parameters is database driver dependent.
parse_dates: list or dict, default: None
1. List of column names to parse as dates.
2. Dict of {column_name: format string} where format string is strftime compatible in case of parsing string times, or is one of (D, s, ns, ms, us) in case of parsing integer timestamps.
3. Dict of {column_name: arg dict}, where the arg dict corresponds to the keyword arguments of pandas.to_datetime() Especially useful with databases without native Datetime support, such as SQLite.
chunksize: int, default None
If specified, return an iterator where chunksize is the number of rows to include in each chunk.
dtype: Type name or dict of columns
Data type for data or columns. E.g. np.float64 or {‘a’: np.float64, ‘b’: np.int32, ‘c’: ‘Int64’}Returns
DataFrame or Iterator[DataFrame]sql = "SELECT * FROM student;"
df = pd.read_sql_query(sql, engine).set_index('id')
df.head()
I have created the student.csv file and added some student records.
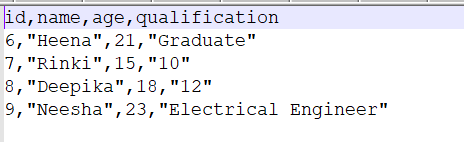
inputFile = '/static/images/nutan/blog/python/student.csv'
students = pd.read_csv(inputFile).set_index('id')
print(students)
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
Write records stored in a DataFrame to a SQL database.
Databases supported by SQLAlchemy [1] are supported. Tables can be newly created, appended to, or overwritten.Parameters
name: str
Name of SQL table.
con: sqlalchemy.engine.(Engine or Connection) or sqlite3.Connection
Using SQLAlchemy makes it possible to use any DB supported by that library.
schema: str, optional
Specify the schema (if database flavor supports this). If None, use default schema.
if_exists{‘fail’, ‘replace’, ‘append’}, default ‘fail’
How to behave if the table already exists.
1. fail: Raise a ValueError.
2. replace: Drop the table before inserting new values.
3. append: Insert new values to the existing table.
index: bool, default True
Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label: str or sequence, default None
Column label for index column(s). If None is given (default) and index is True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
chunksize: int, optional
Specify the number of rows in each batch to be written at a time. By default, all rows will be written at once.
dtype: dict or scalar, optional
Specifying the datatype for columns.
method{None, ‘multi’, callable}, optional
Controls the SQL insertion clause used:
1. None : Uses standard SQL INSERT clause (one per row).
2. ‘multi’: Pass multiple values in a single INSERT clause.
3. callable with signature (pd_table, conn, keys, data_iter).
Details and a sample callable implementation can be found in the section insert method.Raises
ValueError
When the table already exists and if_exists is ‘fail’ (the default).students.to_sql('student', engine, if_exists='append', index=False)
Login to mysql console and write query "select * from student;".
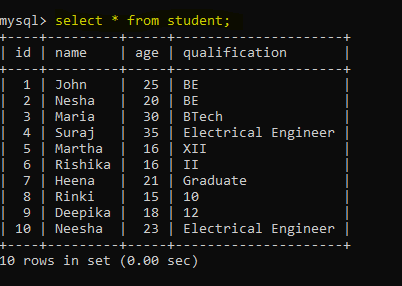
sql = "SELECT * FROM student;"
df = pd.read_sql_query(sql, engine).set_index('id')
df
We can see mysql student table loaded into pandas dataframe. Now whatever you want to do with pandas dataframe, you can do.
new_students = {
'id':[11, 12],
'name':['Roy', 'Mishal'],
'age':[20, 21],
'qualification':['12', 'BE'],
}
new_students
df1 = pd.DataFrame(new_students).set_index('id')
df1
df1.to_sql('student', engine, if_exists='append', index=False)
sql = "SELECT * FROM student;"
df2 = pd.read_sql_query(sql, engine).set_index('id')
df2
import matplotlib.pyplot as plt
df2.plot(kind = "bar")
plt.xlabel("ID")
plt.ylabel("Age")
plt.show()

That's it.